

Table of Contents
Creation:
Knowledge pre-processing is a knowledge mining methodology that comes to remodeling uncooked records into an comprehensible layout. Actual-world records is continuously incomplete, inconsistent, and/or missing in positive behaviors or developments, and is more likely to include many mistakes. Knowledge preprocessing is a confirmed approach of resolving such problems. Once we speak about records, we most often suppose of a few massive datasets with massive selection of rows and columns. Whilst that may be a most likely situation, it isn’t all the time the case — records might be in such a lot of other bureaucracy: Structured Tables, Photographs, Audio information, Movies and so on.
Gadget Finding out algorithms don’t paintings so smartly with processing uncooked records. Ahead of we will be able to feed such records to an ML set of rules, we should pre-process it. In different phrases, we should practice some transformations on it. With records pre-processing, we convert uncooked records right into a blank records set.
The stairs used for Knowledge Pre-processing are: –
- Import Libraries. First step is most often uploading the libraries that shall be wanted in this system.
- Get the Dataset
- Knowledge Exploration or Research
- Caring for Lacking Knowledge in Dataset
- Encoding specific records
- Splitting the Dataset into Coaching set and Check Set
- Characteristic Scaling
We have now used a titanic records set for higher figuring out. It is a very well-known dataset and it’s continuously a pupil’s first step in mechanical device studying classification. We’re going to do elementary pre-processing at the dataset.
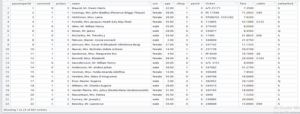
Let’s move forward and get began: –
1)Import Libraries
import pandas as pd import numpy as np import os import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline
- NumPy: -NumPy is a Python library used for operating with arrays. It additionally has purposes for operating in area of linear algebra, Fourier turn out to be, and matrices.
- pandas: -Pandas is used to analyse records.
- seaborn: -Seaborn is a library that makes use of Matplotlib beneath to plan graphs. It’ll be used to visualise random distributions.
- matplotlib: -Matplotlib is a low-level graph plotting library in python that serves as a visualization application.
2)Get the Dataset
- teach = pd.read_csv(“teach.csv”)
The above observation is used to learn dataset into pandas dataframe.
teach is the identify of the dataset and read_csv is a very powerful pandas serve as to learn csv information and do operations on it.
3)Knowledge Exploration/Research

This provides the details about the dataset
- teach.describe()
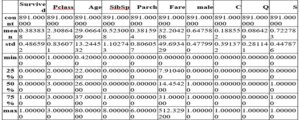
This describes depend, min, max and so on of every column of our dataset
4)Caring for Lacking Knowledge in Dataset
- sns.heatmap(teach.isnull(),yticklabels=False,cbar=False,cmap=’viridis’)

Fig: Heatmap for checking null values

The Long run of Giant Knowledge
With some steerage, you’ll craft a knowledge platform this is proper to your group’s wishes and will get essentially the most go back out of your records capital.
Right here, those yellow dashes display that we have got some lacking knowledge. So, we will be able to simply glimpse on our records from an overly some distance hen’s eye view and take a look at that sure, we’re lacking some age knowledge and numerous Cabin knowledge.
The share of age lacking is most likely smaller for an affordable substitute of a few type of imputation which means we will be able to use the information of alternative columns to fill in cheap values.
Having a look on the cabin column then again it looks as if we’re simply lacking an excessive amount of of that records to do one thing helpful with it at a elementary point. We’re going to most probably drop this column.
There are lots of techniques to regard lacking values, however we’re going to use two of them
1) Impute lacking values with imply/median
2) Deleting rows with lacking values.
We’re going to use Imputation for Age column
- teach[‘Age’].plot.hist(containers=55)
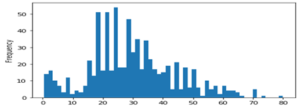
Fig: Histogram for checking age
Right here, we’re going to fill the imply age of the passengers
Alternatively, we will be able to also be a step smarter about this and take a look at the typical age in passenger magnificence.
- boxplot(x=’Pclass’,y=’Age’,records=teach)
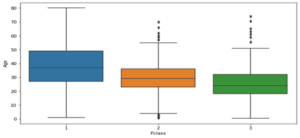
Fig: Boxplot
Beneath is the process we use to impute age column: –
- teach[‘Age’]=teach[[‘Age’,’Pclass’]].practice(impute_age,axis=1)
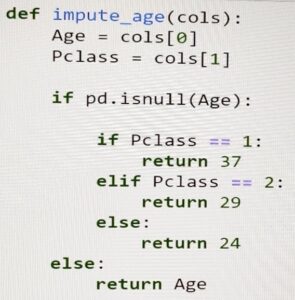 And it looks as if now we’re not having any lacking knowledge for the age column.
And it looks as if now we’re not having any lacking knowledge for the age column.
We effectively installed values that have been cheap guesses for other folks’s age in response to their magnificence.
Now the problem now we have is the cabin column and simply truthfully there’s too many lacking issues to do one thing helpful of this column right here. However there’s simply such a lot lacking knowledge right here that it’s simply more uncomplicated to head forward and drop that cabin column.
- drop(‘Cabin’,axis=1,inplace=True)
5) Encoding specific records
Gadget studying set of rules can’t paintings on specific worth so we can convert them into dummy values. Should you see the intercourse column right here, now we have a specific characteristic of male or feminine. A mechanical device studying set of rules isn’t going with the intention to soak up only a string of male or feminine should create a brand new column in The King a nil or one worth for if somebody is male or now not with the intention to encode that knowledge in some way {that a} mechanical device studying set of rules can comprehend it. Identical applies for embark column.
- intercourse=pd.get_dummies(teach[‘Sex’],drop_first=True)
- embark=pd.get_dummies(teach[‘Embarked’])
- teach=pd.concat([train,sex,embark],axis=1)
- drop([‘Sex’,’Embarked’,’Name’,’Ticket’],axis=1,inplace=True)
6) Splitting the Dataset
Each dataset for Gadget Finding out mannequin should be break up into two separate units – coaching set and take a look at set.
- from sklearn.model_selection import train_test_split
- X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3,random_state=101)

- x_train – options for the educational records
- x_test – options for the take a look at records
- y_train – dependent variables for coaching records
- y_test – unbiased variable for trying out records
Subsequently, the train_test_split() serve as contains 4 parameters, the primary two of which can be for arrays of information. The test_size serve as specifies the scale of the take a look at set. The test_size possibly .5, .3, or .2 – this specifies the dividing ratio between the educational and take a look at units. The closing parameter, “random_state” units seed for a random generator in order that the output is all the time the similar.
7)Characteristic scaling
Characteristic scaling marks the tip of the records pre-processing in Gadget Finding out. This is a option to standardize the unbiased variables of a dataset inside a particular vary. Consequently, characteristic scaling limits the variability of variables to be able to evaluate them on not unusual grounds.
We will be able to carry out characteristic scaling in two techniques: –
1: Standardization
2: Normalization
Conclusion:
So, that’s records processing in Gadget Finding out in a nutshell! At the start, we mentioned Gadget Finding out with Python records pre-processing. Secondly, we mentioned the Knowledge Research and Knowledge Visualization for Python Gadget Finding out. Alternatively, please observe that each and every step discussed right here has a number of extra subtopics that deserve their very own articles. The stairs and strategies we’ve explored are essentially the most used and in style operating strategies. After we’re completed with records preprocessing, records will also be break up into coaching, trying out and validation units for mannequin becoming and mannequin prediction levels. Thank you for studying!
Your opinion issues
Please write your precious comments…
Hyperlinks
https://www.javatpoint.com/data-preprocessing-machine-learning
https://www.upgrad.com/weblog/data-preprocessing-in-machine-learning


