

OVH, the largest hosting provider in Europe and the third-largest in the world, went down earlier today following what looks like routing configuration issues during planned maintenance.
OVH has 32 data centers with over 300,000 servers on four continents and a total of 20 Tbit/s global network capacity.
It provides web hosting, cloud computing services, and dedicated servers to 1,300,000 enterprise customers worldwide.
Outage caused by bad router configuration
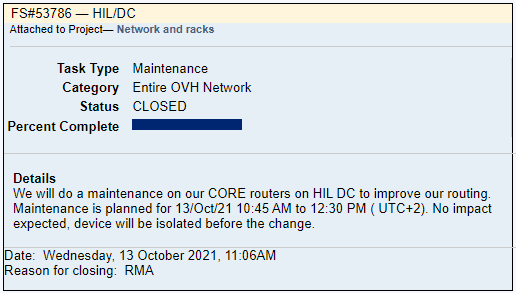
“We will do a maintenance on our routers on VIN DC to improve our routing,” the company said on its status page before its servers went down.
“Maintenance is planned for 13/Oct/21 9:00 AM to 10:30 AM ( UTC+2). No impact expected, device will be isolated before the change.”
However, due to unknown issues encountered during the planned maintenance, the hosting provider’s servers became unreachable, also taking down customers’ sites with them.
“Following a human error during the reconfiguration of the network on our DC to VH (US-EST), we have a problem on the whole backbone. We are going to isolate the DC VH then fix the conf,” OVH founder Octave Klaba explained.
“In recent days, the intensity of DDoS attacks has increased significantly. We have decided to increase our DDoS processing capacity by adding new infrastructures in our DC VH (US-EST). A bad configuration of the router caused the failure of the network.”
According to reports [1, 2], the ongoing outage only affects IPv4 infrastructure, with IPv6 infra still up and reachable over the Internet.
Suite à une erreur humaine durant la reconfiguration du network sur notre DC à VH (US-EST), nous avons un souci sur la toute la backbone. Nous allons isoler le DC VH puis fixer la conf. https://t.co/kDakq7FGBO
— Octave Klaba (@olesovhcom) October 13, 2021
When trying to connect to the OVH website, users are currently seeing “Error 503: Backend unavailable” errors explaining that “This type of error usually results of an unavailability of servers behind IP Load Balancing.”
Visitors are asked to refresh the site or return in a few minutes and reach out to OVH’s support team if the problem persists.
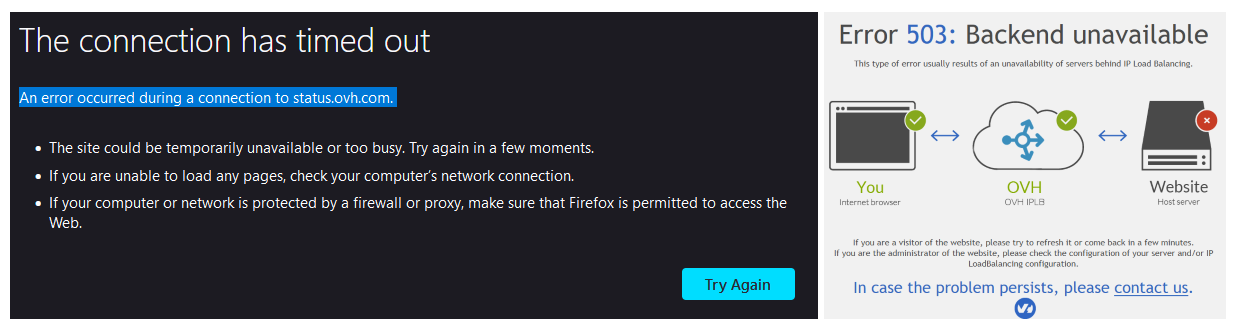
The hosting provider’s status page also went down with the company’s servers during the maintenance process, with the page now displaying “The connection has timed out. An error occurred during a connection to status.ovh.com,” errors.
Earlier his year, major sites also went offline after OVH data centers from Strasbourg, France, burnt down in March.
Its SBG1, SBG2, SBG3, and SBG4 Strasbourg data centers were shut down to contain the damage from the fire that started in SBG2.
The list of impacted clients included videogame maker Rust, provider of free chess server Lichess.org, telecom company AFR-IX, encryption utility VeraCrypt, news outlet eeNews Europe, cryptocurrency exchange Deribit‘s blog and docs sites, the art building complex Centre Pompidou, and many many others.
The company’s founder later explained that SBG2 was an older generation center built in 2011 and that OVH was working towards replacing older infra with newer technology.
Update Oct 13, 04:59 EST: OVH’s network is slowly recovering after it went down 07:20 UTC this morning together with a US router with a faulty configuration.
“Since 08:22 UTC all services are gradually returning following the isolation of network equipment in the US,” the company says.
Klaba tweeted earlier that the router with the wrong D2 configuration has been cut from the network.

Update Oct 13, 06:01 EDT: OVH says services have been now restored.
On the morning of October 13 at 9:12 am (CET / Paris time), we carried out interventions on a router at our Vint Hill Datacentre in the United States, which caused disruptions on our entire network. These interventions were aimed at strengthening our anti-DDoS protections, attacks which have been particularly intense in recent weeks.
OVHcloud teams quickly intervened to isolate the equipment at 10:15 am. Services have been restored since this intervention.
We are currently running a verification campaign with our clients to confirm the restoration of all their services.
We offer our sincere apologies to all of our impacted customers and will be as transparent as possible about the causes and consequences of this incident.
https://www.bleepingcomputer.com/news/technology/ovh-hosting-provider-goes-down-during-planned-maintenance/


